
هوش مصنوعی در خدمت توسعه مواد باتری
امروزه میزان دادههای تحقیق و توسعه باتری بهطور تصاعدی افزایش مییابدBASF، دومین تولید کننده مواد شیمیایی در جهان، اعلام کرده که بیش از 70 میلیون نقطه داده مشخصات باتری در روز تولید می کند. برای رعایت عدالت حجم عظیمی از داده ها در نشریات علمی پخش شده است اما محققی که سالانه 200 مقاله میخواند، تقریباً به 150 سال زمان نیاز دارد تا تمام انتشارات LIB را که امروزه در دسترس است بخواند. برای افزایش سرعت کشف مواد برای کاربردهای انرژی، هوش مصنوعی (AI) و به ویژه شاخه پربار آن به نام یادگیری ماشین (ML) به عنوان یک رویکرد امیدوارکننده برجسته است که می تواند منجر به تغییر الگو در روش تحقیق و توسعه باتری شود و ما را قادر می سازد تا بر چالش های عمده ای که با تعداد زیادی از متغیرها و حجم زیادی از داده ها سر و کار دارند غلبه کنیم.
تحقیق و توسعه باتری یک مسئله پیچیده چند متغیره است که در آن ویژگیهای بسیار متفاوتی مانند عملکرد، تجزیه و تحلیل چرخه عمر، ایمنی، هزینه، اثرات زیستمحیطی و مسائل مربوط به منابع وجود دارد. علاوه بر این، چرخه باتری که از مرحله استخراج، تولید و مونتاژ وبازیافت نهایی در نظر گرفته شود. با این حال، گردش کار تحقیق حاضر به آزمایش و خطای رو به جلو متکی است و عمدتاً بر سنتز مواد، تولید الکترولیت ها و الکترودها، مونتاژ سلول ها، و در نهایت ارزیابی عملکرد متمرکز است. با در نظر گرفتن این جنبه ها، تعداد زیادی احتمال برای سنتز مواد فعال و تهیه الکترولیت، انتخاب پارامترهای ساخت الکترود و ده ها فرمت سلولی وجود دارد که بسیار بیشتر از آن چیزی است که مغز انسان می تواند تحمل کند.
جایگاه هوش مصنوعی و دیگر ابزارها در کشف مواد جدید
روشهای محاسباتی متنوعی برای بدست آوردن کشف ترکیبات جدید در مواد وجود دارند، بیشترین چالش درعلم طراحی مواد، ساختار بلوری آنهاست، زیرا طراحی مواد برپایه دانش ساختار بلوری آنها قرار دارد. روشهای قدیمی برپایه بدست آوردن انرژی استوار هستند به این صورت که در طی مراحل زیادی نیروها و انرژیها مدام محاسبه میشود تا اینکه به ساختار پایدار ترمودینامیکی برسند به همین خاطر این روشها دارای هزینههای محاسباتی زیادی هستند. روش ماشین یادگیری، میتوانند از چند جهت بر این مشکل فایق بیایند، اول اینکه چندین برابر سریعتر از روشهای قدیمی عمل میکنند، دوم در پیشبینی اجزای ترکیب به جای روبش فضای ساختار برای یک ترکیب یک ساختار نمونه انتخاب میکند و فضای ترکیب منتخب را برای ماده پایدار روبش میکند در این روش پایداری ترمودینامیکی مفهوم اساسی است. البته باید توجه داشت که روش ماشین یادگیری و هوش مصنوعی با یکدیگر تفاوت دارند به این صورت که ماشین یادگیری با استفاده از دادههای تجربی الگویی را برای خصوصیت مورد توجه پیدا میکند در حالیکه در هوش مصنوعی دادههای تجربی را برای بدست آوردن دانش و مهارت بکار میبرد و اینکه آنها را به محیط-های جدید تعمیم میدهد. شکل 1 موقعیت روش ماشین یادگیری به هوش مصنوعی را نشان میدهد.
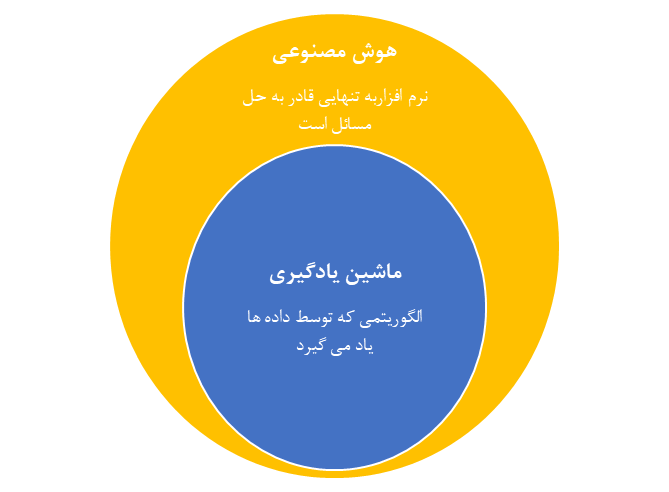
شکل 1. موقعیت روش ماشین یادگیری نسبت به هوش مصنوعی
روشهای ماشین یادگیری و انواع شبیهسازیها به پیشبینی خواص و خصوصیات ماده میپردازند اما از نظر عملکرد متفاوت هستند. شکل 2 تفاوتهای بین روشهای DFT و ماشین یادگیری را به طور شماتیک نشان داده است.
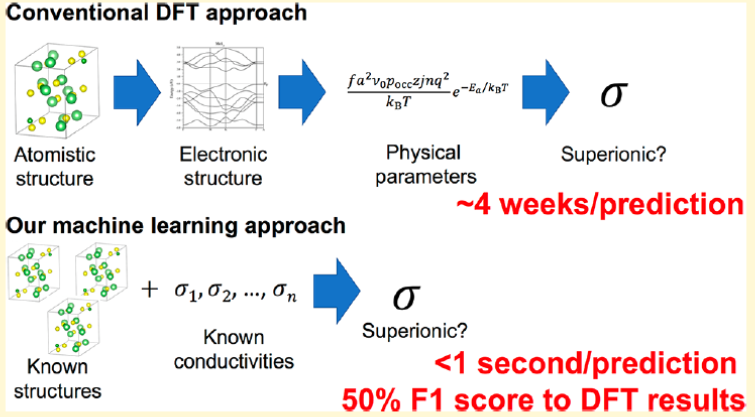
شکل 2. تفاوت بین روش DFT و روش ماشین یادگیری در پیش بینی مواد جدید
دانش مواد جدید از طریق محاسبات، هدفش کشف مواد از ترکیب ریاضیوار الگوریتمها و علم محاسباتی مواد است.
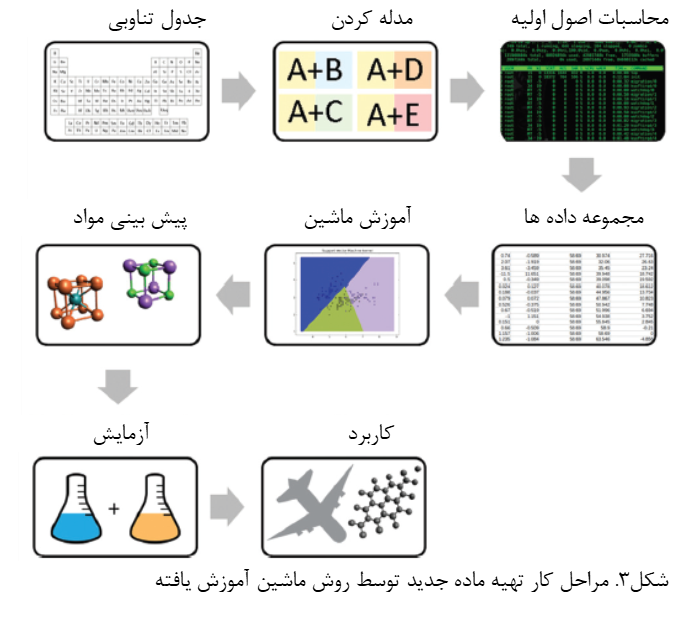
همه الگوریتمهای ML بر مقدار دادهها تکیه میکنند که برای توسعه مدلهای ML دقیق ضروری هستند. اعتقاد بر این است که مقادیر بیشتر دادهها منجر به مدل های ML دقیقتر میشود، البته کیفیت دادهها نیز عامل بااهمیتی است. به عنوان مثال مجموعههای دادهای که حاوی دادههای بسیار کم یا حاوی دادههای با کیفیت پایین هستند، میتوانند منجر به پیشبینیهای اشتباه ML شوند و تفسیر نتایج مرتبط را سوگیری کنند. انواع الگوریتم براساس نیاز توسعه یافته است که انتخاب هر کدام از مدلها براساس دادههای ورودی، خصوصیات مورد بررسی و سطح دقت محاسبات انتخاب میشوند. در ادامه مراحل کشف مواد جدید توسط روش ماشین یادگیری در شکل 3 به طور شماتیک نشان داده شده است.
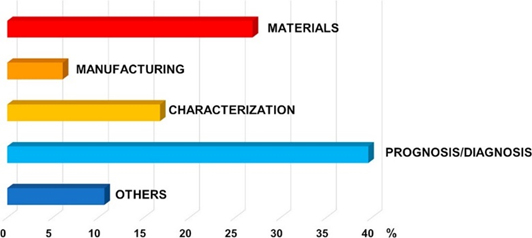
شکل درصد مقالاتی که هوش مصنوعی یا ML را در بررسی موضوعات مختلف مرتبط با باتری به کار برده اند را نشان میدهد. این تحلیل بر روی 200 مقاله علمی انجام شده است، همانطور که مشاهده میشود بیشترین کاربرد برای حوزه مشخصهیابی و مواد بوده است.
کاربرد در طراحی و کشف مواد
کشف و بهینهسازی مواد به کمک انفورماتیک در حال تبدیل شدن به یک ابزار قدرتمند برای تجزیه و تحلیل دادههای تجربی و نظری و استخراج روابط ساختاری و خصوصیات کلیدی مواد مواد باتری است .
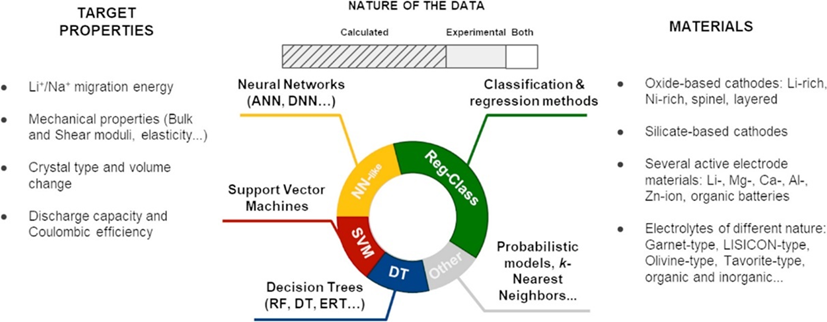
شکل 4: انواع روشهای بکار گرفته شده برای یافتن مواد جدید در باتریها (Chem. Rev. 2022, 122, 12, 10899)
یکی از جذابترین تحقیقات در ارتباط با شناسایی ماده توسط هوش مصنوعی این باشد که اخیرا پژوهشگران مایکروسافت و آزمایشگاه ملی شمال غرب اقیانوس آرام یا PNNL در مقالهایی مجله JACKS گزارش دادند. در طی این تحقیق، 23 ماده امیدوارکننده را ازمیان 32 میلیون نامزد توسط ML شناسایی شدند.
محققان الکترولیت جامد را موضوع این تحقیقات قرار داده بودند که یکی از امیدوارکننده مواد در حوزه بهبود خصوصیات باتریها به شمار میآیند. در باتریهای لیتیوم یون رایج، الکترولیت مایع است. اما این با خطراتی مانند نشت باتری یا ایجاد آتش سوزی همراه است. ساخت باتریهایی با الکترولیتهای جامد یکی از اهداف اصلی دانشمندان مواد است.
در این تحقیق32 میلیون نامزد اولیه از طریق ترکیب و تطبیق مواد ایجاد شدند همچنین در مواردی عناصر مختلف را در ساختارهای کریستالی مواد شناخته شده جایگزین کردند. این در حالی است که مرتبسازی فهرستی به این بزرگی با محاسبات فیزیک سنتی، دههها سال طول میکشید. اما با استفاده از تکنیکهای یادگیری ماشینی این محاسبات تنها در 80 ساعت به نتایجی دست یافت.
ابتدا، محققان از هوش مصنوعی برای فیلتر کردن مواد بر اساس پایداری استفاده کردند، یعنی اینکه آیا واقعاً میتوانند در دنیای واقعی وجود داشته باشند یا خیر. بدین ترتیب فهرست به کمتر از 600000 نامزد کاهش یافت. تجزیه و تحلیل بیشتر هوش مصنوعی، نامزدهایی را انتخاب کرد که احتمالاً خواص الکتریکی و شیمیایی لازم برای باتریها را دارند. از آنجایی که مدلهای هوش مصنوعی تقریبی هستند، محققان این فهرست کوچکتر را با استفاده از روشهای آزمایششده و محاسباتی فشرده مبتنی بر فیزیک فیلتر کردند. آنها همچنین مواد کمیاب، سمی یا گران قیمت را حذف کردند.
این باعث شد که محققان 23 نامزد داشته باشند که پنج تا از آنها قبلاً شناخته شده بودند. محققان PNNL مادهای را انتخاب کردند که امیدوارکننده به نظر میرسید، این ماده به مواد دیگری که محققان میدانستند چگونه در آزمایشگاه بسازند، مرتبط بود و از ثبات و رسانایی مناسبی برخوردار بود. سپس شروع به سنتز آن کردند و در نهایت آن را به یک باتری نمونه اولیه تبدیل کردند.
تمام این فرآیند شامل مرحله سنتز به باتری عملکردی حدود شش ماه طول کشید که می توان آن را فرآیند فوق سریع در این حوزه نامید.
الکترولیت جدید شبیه ماده شناخته شده حاوی لیتیوم، ایتریم و کلر است، اما مقداری لیتیوم را با سدیم تعویض کردهاند که از نظر قیمت و مسائل زیست محیطی بهبود یافته است.
روش معمول استفاده از یونهای لیتیوم یا سدیم به عنوان عامل انتقال مرسوم هستند، اما کاربرد هر دو زیاد مطلوب نبود است زیرا انتظار میرود که دو نوع یون با یکدیگر رقابت کنند و در نتیجه عملکرد بدتری داشته باشند که در این تحقیق عکس این انتظار مشاهده شده است. در این کار محققان مجموعهای از مدلهای هوش مصنوعی را ایجاد کردند که میتواند ویژگیهای مختلف یک ماده را براساس دادههای آموزشی از مواد شناخته شده پیشبینی کند. هوش مصنوعی مورد کاربرد در این تحقیق که با شبکه عصبی گراف شناخته میشود، شامل یک نمودار با ساختار ریاضی متشکل از "لبه ها" و "گره ها"، که همان سیستم است، این نوع مدل به ویژه برای توصیف مواد مناسب است، زیرا گرهها میتوانند اتمها را نشان دهند و لبهها می توانند پیوندهای بین عناصر را نشان دهند.
برای انجام محاسبات مبتنی بر هوش مصنوعی و فیزیک، از عناصر کوانتومی Azure مایکروسافت استفاده شد که امکان دسترسی به یک ابر رایانه مبتنی بر ابر را برای تحقیقات شیمی و علم مواد فراهم میسازد.
این مطالعه یکی از چندین تلاش برای استفاده از هوش مصنوعی برای کشف مواد جدید است. در ماه نوامبر نیز محققان Google DeepMind از شبکههای عصبی نموداری برای پیشبینی وجود صدها هزار ماده پایدار استفاده کردند، که در مجله Nature به چاپ رسید.
چالشها و دیدگاهها
با وجود اینکه هوش مصنوعی و ML می تواند به محققان کمک کنند تا به طور موثر پارامترها و چالشهای داده LIB ها را حل کنند و همچنین به تحقیق و توسعه فناوریهای باتریهای نوظهور کمک میکند. روشهای مبتنی بر ML میتوانند در پیشرفت شیمی، فرمولبندی و شرایط عملیاتی باتری موثر باشد و موجب کاهش تعداد آزمایشها و/یا محاسبات مورد نیاز شود. اما ML در آینده نزدیک به ذخایر داده اختصاصی بزرگی نیاز خواهد داشت. اگر منابع علمی در دسترس را برای این منظور در نظر بگیریم، باز کمبود سیستماتیک دادهها در موارد خواص الکترود و سلول وجود دارد به عنوان مثال، تخلخل الکترود، حجم الکترولیت، یا پروتکلهای آزمایش الکتروشیمیایی می توانند از این موارد باشند.
چالش هایی که باید برای توسعه کاربرد ML به آنها پرداخته شود را می توان در پنج گروه شامل (1) توصیف کننده ها، (2) کمبود داده¬ها و تعیین خطا، (3) فقدان استانداردها در نمایش، (4) ابزارهای کاربرپسند، و(5) مقیاسهای پل زدن خلاصه کرد:
• توصیفگرها: کارایی و در نهایت موفقیت هر مدل ML به انتخاب توصیفگرهای مناسب بستگی دارد. تعریف مناسبترین توصیفگرها برای یک مدل ML خاص و شناسایی توصیفگرهایی که میتوان آنها را تعمیم داد، چندان ساده نیست. حتی با وجود اینکه اهمیت توصیفگرهای خوب تا حد زیادی در زمینه ML به کار رفته در طراحی و سنتز مواد مورد بحث قرار میگیرد، همین مشکل در مورد سایر زمینههای مورد بحث از تولید تا مشخصهیابی مواد نیز صدق میکند.
• کمبود داده و تعیین خطا: اگر از یک طرف تعداد توصیفگرها/پارامترهای ممکن در هر روش ML می تواند زیاد باشد، از طرف دیگر اندازه مجموعه دادههای آموزشی به خصوص در مقیاس آزمایشگاهی میتواند نسبتاً کوچک باشد. این عدم تعادل ممکن است، به طور کلی، منجر به مشکلاتی شود. برای کاهش این امر، تحقیقات آینده باید طراحی و توسعه الگوریتمهای ML به طور خاص برای مجموعه دادههای کوچک همانند ML سلسله مراتبی، یادگیری تقویتشده، یادگیری متوالی و غیره مورد بررسی قرار دهند. علاوه بر این، تکنیکهای ML که قادر به تعیین یا تخمین خطای مرتبط با پیشبینیهای ML هستند، بسیار سودمند خواهند بود و به ارزیابی محدودیت کاربرد یک مدل خاص ML اجازه میدهند که برای دامنه گستردهتری از رویکردهای ML مطلوب باشد.
• فقدان استانداردها و نمایشهای نابالغ: فقدان استانداردهای داده در زمینه باتری نه تنها مانع از اشتراک گذاری و استخراج دادهها میشود، بلکه مانع از پردازش داده ها و قابلیت همکاری می شود، که برای بهبود قابلیت پیشبینی مدلهای ML و ایجاد آنها بسیار مهم است.
• ابزارهای کاربرپسند: همکاری قویتر بین متخصص هوش مصنوعی و کارشناسان باتری از نظر تجربی و محاسباتی برای بهرهبرداری از پتانسیل کامل رویکردهای هوش مصنوعی یا ML به کار رفته در تحقیق و توسعه باتری بسیار مهم است. یک استراتژی احتمالی برای تسهیل پذیرش گستردهتر رویکردهای مبتنی بر داده در روال معمول یک محقق باتری میتواند توسعه ابزارهای کاربرپسند مبتنی بر هوش مصنوعی یا ML باشد. هدف این ابزارها کمک به پژوهشگران در کار روزانه شان است، که باعث می شود آن ابزارها را تا حد امکان با داده های بیشتری تغذیه کنند و احتمالاً چالش های مرتبط با کمبود داده را کاهش دهند.
• مقیاسهای پل زدن: ML نقش مهمی برای توسعه مدلهای چند بعدی (از سطح اتمی تا سیستمی) برای ساختن مدلهای پیشبینی و محاسبه همه مقیاسها و تعاملات آنها دارد. به عنوان مثال، استفاده از تکنیکهای تصویربرداری مبتنی بر ML میتواند بینشهای ارزشمندی در مورد پویایی فرآیندهای سطحی ارائه دهد، که تشکیل و رشد دندریت لیتیوم یکی از مضرترین این پدیدهها است. چنین مدلهایی میتوانند به یک دیدگاه جامعتر از مسئله بهینهسازی باتری منجر شوند و مرزهای جدیدی را در تحقیق و توسعه و توسعه باتری باز کنند.